Digital Image Definitions |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| A
digital image a[m,n] described in a 2D discrete
space is derived from an analog image a(x,y) in a
2D continuous space through a sampling process that is frequently
referred to as digitization. The mathematics of that sampling process
will be described in Section 5. For now we will look at some basic
definitions associated with the digital image. The effect of
digitization is shown in Figure 1. The
2D continuous image a(x,y) is divided into N
rows and M columns. The intersection of a row and a
column is termed a pixel. The value assigned to the integer
coordinates [m,n] with {m=0,1,2,...,M-1} and
{n=0,1,2,...,N-1} is a[m,n]. In fact,
in most cases a(x,y)--which we might consider to be
the physical signal that impinges on the face of a 2D sensor--is
actually a function of many variables including depth (z), color
(
Figure
1:
Digitization of a continuous image. The pixel at coordinates [m=10,
n=3] has the integer brightness value 110. The image shown in Figure 1 has been divided into N = 16 rows and M = 16 columns. The value assigned to every pixel is the average brightness in the pixel rounded to the nearest integer value. The process of representing the amplitude of the 2D signal at a given coordinate as an integer value with L different gray levels is usually referred to as amplitude quantization or simply quantization.
|

|
Parameter
|
Symbol |
Typical values |
|
Rows |
N |
256,512,525,625,1024,1035 |
|
Columns |
M |
256,512,768,1024,1320 |
|
Gray Levels |
L |
2,64,256,1024,4096,16384 |
Table 1: Common values of digital image parameters
Quite
frequently we see cases of M=N=2K where
{K = 8,9,10}. This can be motivated by digital circuitry or by
the use of certain algorithms such as the (fast) Fourier transform (see
Section 3.3).
The
number of distinct gray levels is usually a power of 2, that is, L=2B
where B is the number of bits in the binary representation of the
brightness levels. When B>1 we speak of a gray-level image;
when B=1 we speak of a binary image. In a binary image
there are just two gray levels which can be referred to, for example, as
"black" and "white" or "0" and
"1".
![]()
Characteristics of Image Operations
![]()
There
is a variety of ways to classify and characterize image operations. The
reason for doing so is to understand what type of results we might
expect to achieve with a given type of operation or what might be the
computational burden associated with a given operation.
Types of operations
The types of operations that can be applied to digital images to transform an input image a[m,n] into an output image b[m,n] (or another representation) can be classified into three categories as shown in Table 2.
|
Operation
|
Characterization |
Generic Complexity/Pixel |
|
* Point |
- the output value at a specific coordinate is dependent only on the input value at that same coordinate. |
constant |
|
* Local |
- the output value at a specific coordinate is dependent on the input values in the neighborhood of that same coordinate. |
P2 |
|
* Global |
- the output value at a specific coordinate is dependent on all the values in the input image. |
N2 |
Table 2: Types of image operations. Image size = N x N; neighborhood size = P x P. Note that the complexity is specified in operations per pixel.
This
is shown graphically in Figure 2.

Figure 2:
Illustration of various types of image operations
Types of neighborhoods
Neighborhood operations play a key role in modern digital image processing. It is therefore important to understand how images can be sampled and how that relates to the various neighborhoods that can be used to process an image.
*
Rectangular sampling - In most cases, images are sampled by laying a
rectangular grid over an image as illustrated in Figure 1. This results
in the type of sampling shown in Figure 3ab.
*
exagonal sampling - An alternative sampling scheme is shown in Figure 3c
and is termed hexagonal sampling.
Both
sampling schemes have been studied extensively and both represent a
possible periodic tiling of the continuous image space. We will restrict
our attention, however, to only rectangular sampling as it remains, due
to hardware and software considerations, the method of choice.
Local
operations produce an output pixel value b[m=mo,n=no]
based upon the pixel values in the neighborhood of a[m=mo,n=no].
Some of the most common neighborhoods are the 4-connected neighborhood
and the 8-connected neighborhood in the case of rectangular sampling and
the 6-connected neighborhood in the case of hexagonal sampling
illustrated in Figure 3.
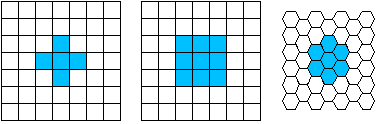
Figure
3a Figure 3b Figure 3c
Rectangular sampling Rectangular sampling exagonal sampling 4-connected 8-connected 6-connected
![]()
Video Parameters
We do not propose to describe the processing of dynamically changing images in this introduction. It is appropriate--given that many static images are derived from video cameras and frame grabbers-- to mention the standards that are associated with the three standard video schemes that are currently in worldwide use - NTSC, PAL, and SECAM. This information is summarized in Table 3.
|
Standard
|
NTSC |
PAL |
SECAM |
|
Property |
|
|
|
|
images / second |
29.97 |
25 |
25 |
|
ms / image |
33.37 |
40.0 |
40.0 |
|
lines / image |
525 |
625 |
625 |
|
(horiz./vert.) = aspect ratio |
4:3 |
4:3 |
4:3 |
|
interlace |
2:1 |
2:1 |
2:1 |
|
us / line |
63.56 |
64.00 |
64.00 |
Table 3: Standard video parameters
In
an interlaced image the odd numbered lines (1,3,5,...) are scanned in
half of the allotted time (e.g. 20 ms in PAL) and the even numbered
lines (2,4,6,...) are scanned in the remaining half. The image display
must be coordinated with this scanning format. (See Section 8.2.) The
reason for interlacing the scan lines of a video image is to reduce the
perception of flicker in a displayed image. If one is planning to use
images that have been scanned from an interlaced video source, it is
important to know if the two half-images have been appropriately
"shuffled" by the digitization hardware or if that should be
implemented in software. Further, the analysis of moving objects
requires special care with interlaced video to avoid "zigzag"
edges.
The number of rows (N) from a video source generally corresponds one-to-one with lines in the video image. The number of columns, however, depends on the nature of the electronics that is used to digitize the image. Different frame grabbers for the same video camera might produce M = 384, 512, or 768 columns (pixels) per line.